Music Video of the Day: Dizzee Rascal, Bass Junkie (NSFW-ish language)
(Source: https://www.youtube.com/)
Software Raconteur
Music Video of the Day: Dizzee Rascal, Bass Junkie (NSFW-ish language)
Nostalgic Music Video of the Day: Presidents of the United States of America, “Peaches”
[Note: this post is adapted from a long comment I made on one of Albert Wenger’s recent posts]
Albert, I think you’re absolutely right that the search game is just getting going. If you define search as “finding relevant web pages,” then Google has search locked up and solved. But if you define search as “providing the information you need to make the best decisions all the time” then there’s a vast and fertile green field ahead. At the end of the day, the goal of search isn’t to deliver links – it’s to deliver wisdom.
So how are we going to do that?
Let’s start with a thought experiment: imagine that you yourself are hired to be a search engine. Now imagine that your wife is a search user and so naturally any time she needs something you want to give her the absolute best and most useful answers you can.
Let’s assume that you have unlimited time, resources, and patience to search. But let’s add a constraint: the only way your wife can communicate is by barking 2-10 words at you and waiting silently.
How you would go about answering your wife’s queries?
For example, let’s say she asks “pizza broadway.” You can probably guess what she wants, but at least for me Googling that phrase returns junk. You, on the other hand, would take what you know about your wife’s tastes, then you’d compile a list of restaurants on Broadway, then you’d figure out which ones serve pizza, then you’d look at Yelp to see how well reviewed each pizza place is, and then perhaps you’d call your friends who eaten at those restaurants to get their opinion (which you would discount based on how much you trusted their taste in pizza.) Ultimately you’d hand your wife a simple summary telling her that the best pizza on Broadway was at “Pizza X,” located at 3333 Broadway (click here for directions or here to have it delivered.) You might even provide a summary of why you chose that answer if it was a close call.
Next consider a slightly more complicated (but much more important) query: “best college for my child.” Even with your human judgment and everything you know about your wife and children, that’s a mighty hard question to answer. But it’s not impossible, and it probably has an objectively correct answer (or at least there’s a small set of equivalently good options.)
So how would you get to the answer? Personally, I would start by fighting back against the initial constraint of this thought experiment, i.e. that you can’t communicate with the searcher. I’m sure you’d be able to do a much better job of answering the college query if you could have a conversation with your wife that lets her volunteer additional relevant information (e.g. whether your kid prefers small or big schools.) That additional information would let you figure out which variables to optimize and thus come up with a much better answer.
I’m using this thought experiment to try to make three points:
1) Search is a much larger and much more economically and socially valuable problem than “find the best link.”
2) A great answer to a hard question requires sophisticated aggregation of information from a variety of sources.
3) Instead of starting with an interface (e.g. “text in a box”) and figuring out how to
stretch that approach, one should start by figuring out what information one
needs from the user and then design the interface to most effectively gather
that information.
Facebook’s graph search is extremely exciting because it’s the first approach I’ve seen by a large player that recognizes each of those three principles:
1) Graph search lets you solve an entirely new class of problems. As a real life example – last week I spent about 20 minutes compiling a list of people to invite to my
birthday party. I could have done that in an instant by querying “close friends
who live in New York.”
2) The whole system is based on Facebook’s massive structured dataset. Cost-of-data-acquisition was what killed off the 1980’s “question answering” AI systems, but Facebook has basically solved that problem by conscripting an army of human volunteers.
3) It’s still a textbox, but the addition of the “concept chaining” system (i.e. “in New York”, “from 2003”) lets users massively but easily increase the expressive power of
their queries.
Obviously it’s going to be a long, long time before a computer can tell your children where to go to college. But it’s going to happen.
The search systems of the future aren’t going to be location-based OR mobile OR social. They’re going to be all of the above. They’re going to combine cutting-edge machine learning and NLP with crowd-sourcing and old-fashioned manual data entry to create comprehensive, varied knowledge bases. They’re going to use embarrassingly parallel systems to process data that’s organized with ontologies from linked data and stored in not-only-SQL data-stores. And they’re going to use best-practices from Human Computer Information Retrieval (HCIR) to expose interfaces that let searchers effortlessly deploy statistical reasoning to get the exact answers they need to live better lives.
Imagine a world where your mobile phone can instantly find every band similar to your favorite bands you’ve never heard, or can provide you all the core evidence for and against investing in an entrepreneur, or can save you hundreds of millions of dollars by correctly estimating how many factories you need to build to meet demand for your new widget.
Those answers are coming. And they’re coming soon.
[Edit: if you like this post, help more people see it! Please share, or upvote this post in the Hacker News “new” queue ]
I was not a normal child. At age 2, my favorite pastime was disassembling every child safety device my parents bought. By age 4, I had become an avid user of the original Macintosh (despite being unable to read.) When I hit school, I was… ”impatient” with the pace of the curriculum. Luckily, I had great parents. They were interested enough to provide me with an endless supply of books and extracurricular excursions. They were savvy enough to maneuver me into an excellent charter middle school. And they were affluent enough to send me to a private high school where the teachers stuffed me with knowledge instead of letting the students stuff me into lockers.
Not all children are so lucky. I’m no social scientist, nor am I particularly well informed about the particulars of the American public educational system. What I am is strongly convinced that educational opportunities make an exceptional difference in the life of a gifted child. And that every gifted child in America – irrespective of background – deserves at least the same opportunities I had.
Last week, I read an article in the New York Times about the continued under-availability of gifted and talented (G&T) education, especially to minority students. In our era of unbelievably insane and misguided budget madness, education is something of an easy target. Children, of course, don’t vote. And G&T education is often seen as a luxury which can be cut or as a competitor for a fixed number of education dollars (especially against programs like special education.)
So, naturally, while falling asleep last night I decided to estimate the actual cost vs. benefit of gifted education. The results were somewhat surprising, so I’d like to share them with you.
In short, the conclusion is that it literally costs the government $0 to spend up to $6,500 extra per pupil per year on gifted education. That’s approximately 50% more than the U.S.A. currently spends on the average pupil.
That sounds like a lot, right? Here’s how I got there:
First, we need a few simplifying assumptions:[1]
· Students can be ranked into deciles by academic aptitude [2]
· Annual income is related to academic aptitude by a power law distribution [3]
· A well-targeted education program can raise the average annual income of a decile by 5% [4]
From there, the logic is simple. The annual median income for men in the USA is ~$45k [5]. We assume that the least a worker in the USA can make in a year is $10k [6]. We then roughly fit a power law distribution using income data reported by the U.S. Census Bureau (which has a pretty clear power law shape.)

(source)
This lets us predict annual income by academic decile:
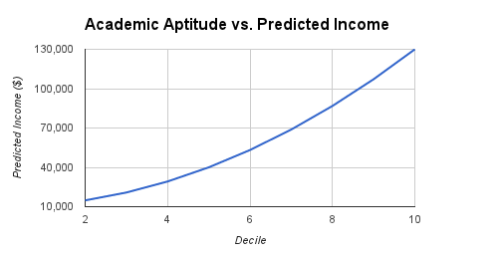
From there, we can predict lifetime income by simply multiplying annual income by the average number of working years (assumed to be 43)[7]. We then multiply lifetime income by our education “bonus” multiplier (5%) to get the additional income each student is expected to generate over her lifetime. We then assume that the government will take back 30% of that extra income through taxes. We divide those collections by the number of years a student spends in school (13), and we have our annualized “free money” threshold, i.e. an amount of spending per pupil that will generate a positive return on investment for the government.[8]
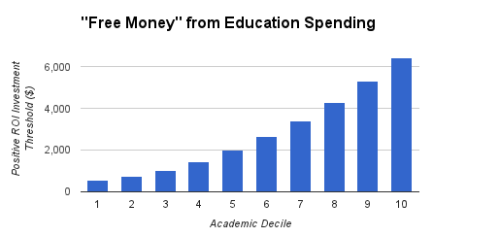
This chart shows the conclusion:
If you’d like to see the calculations step-by-step or you’d like to adjust my assumptions, take a look at this Google doc.
What does this chart say, exactly? It says that if the government spends an additional $5,000 per year on a gifted student, it can expect to collect more back in income taxes over her life than it spent on her gifted education. In other words, up to a point (i.e. $6,500) spending on gifted education is literally free for the government.
That means that any debate about prioritizing gifted vs. special needs education is deeply misguided. It’s not an either/or question. The only reasonable course of action is to just spend the money on gifted education and make all other education spending decisions independently. The government need not even raise taxes to fund the programs; they could issue a 30-year municipal bond and expect to be able to pay back the interest with the extra taxes they collect.
Now this analysis is obviously an oversimplification. Everyone knows that being smart per se does not guarantee a high income.[9] It’s crude at best to assume a static and binary 5% boost in income from simply having a gifted program. And this analysis completely ignores the many social benefits of having better prepared doctors and scientists[10]. I discuss a number of other specific flaws in the footnotes.
Nevertheless, I think the conclusion is sound. Opportunities for accelerated education made a huge difference in my life, and it’s a tragedy that talented students continue to be denied those opportunities just because of their parents’ income. Whether the USA recognizes that fact, China and India certainly will.
Notes:
[1] Relevant data was hard to find on a cursory Google search. If you have better data or feel like making more sophisticated models, please post in the comments!
[2] The idea of innate academic aptitude is controversial enough even without specifying a yardstick. So choose your own! The method of measurement doesn’t affect the logic as long as a measurement can be made.
[3] It’s pretty clear that income itself follows a power law distribution. I’ve never seen a good study about how well academic aptitude predicts income, but to whatever extent America actually is a meritocracy: it will. For every maxim about “A students work for C students”, I’ve met very few unintelligent people who’ve earned large amounts of money.
[4] I pulled this number out of a hat. Intuitively and based on my own experience, I suspect it’s significantly higher. But I wanted to be conservative for the analysis.
[5] The median income for women is substantially lower, but I’m assuming that’s because homemakers are counted. Assuming men and women have equal earning potential if they actually do work, using male income shouldn’t affect the conclusion.
[6] A bit less than full-time minimum wage income, since unemployment rates are much higher for the less educated. http://poverty.ucdavis.edu/faq/what-are-annual-earnings-full-time-minimum-wage-worker
[7] Working from 22-65
[8] I’m ignoring any time-value-of-money issues, both because that would be complicated and because I figure that wages should grow approximately at the interest rate, so discounting vs. wage inflation should cancel out.
[9] In an era where a good data scientist can earn $300,000…we’re getting close. Many top decile people will chose lower income careers, but they will have had at least the option to earn more if they chose.
[10] Medical, technological, and scientific discovery probably also follow a power law distribution. So we should expect that giving our brightest scientists more education will significantly increase the rate of discovery.
I make a point of trying as many new startup products as I reasonably can. Quite a lot use a freemium model where they offer me some free service and then pester me to upgrade to the $10/month “pro” version. Out of dozens of products I’ve tried over the last couple of years, I’ve upgraded to the pro version approximately three times (Dropbox, Github, Spotify.)
Why so few? Sometimes the product is just bad. Sometimes it’s targeted at a real problem I don’t have. But in a surprising number of cases, I’m not upgrading because the startup is using a freemium model that just doesn’t make sense.
My basic contention in this post is that in many freemium startups, the free product is the real product and the “pro” product is just a bunch of random tacked-on features that might appeal to power users. Instead, startups should remember that the premium product is the real product, and the free version is just a conduit to make people aware that paying money will actually solve their problem.
Now I’ve never managed a freemium model myself, so these are just common sense observations. I may be missing the deep inner logic of particular programs are particular startups. But in too many cases, it’s mighty hard to imagine how what I’m seeing could make sense.
The Wrong Way:
Let’s start with some basic logic:
1) Your startup is in business to make as much money as possible [1]
2) The amount of money you make equals (the number of people paying you, i.e. your customers) X ($ per customer)
3) To maximize your revenue, you need to simultaneously maximize your # of customers and your $/customer
So far, so good. But let’s pause for one crucial point. Only people who pay you are customers. Everyone else, including non-paying users of your service, are not customers. That’s not to say they aren’t lovely people, or that they may not serve a critical business purpose like word-of-mouth marketing or generating content, but they don’t pay you and so they are not customers.
Now the logic behind the freemium model is:
4) We will offer a free service and a premium service (for $X)
5) Some % of users will be willing to pay $X to become premium users (i.e. customers)
6) So we need to acquire as many free users as possible to maximize our # of customers and therefore our revenues.
Sound reasonable? No!
There’s a gaping logic hole between #5 and #6, and it swallows many startups.

(Artist’s rendition of a logic hole)
The problem is the assumption that you’ll be able to convert a constant % of users into customers.
Let’s say you’re a fitness tracking app, for example DailyBurn (which I use)[2]. You launch your core product, a calorie and workout tracker. It’s free to use, and after a month you’ve got 10k users. Great! But you’re running a bit low on cash, so you decide to get started on the “mium” part, and you launch a set of “pro" features like the ability to save more favorite foods and to plan meals in advance:
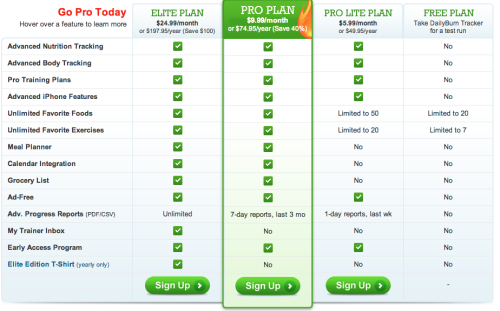
Five hundred users (5%) sign up for the $10/month pro plan, and suddenly you’re making $5k a month in revenue. Not only can keep your servers on, you can also afford some calories for yourself to track.
$5k/month is great, you think, but this means that if I had 10 million users then I’d have 500,000 customers and I’d be making $5 million dollars a month!
Of course, this story very rarely ends well. The startup devotes all of its resources into improving and marketing its core free product, and (in the good case) actually gets a large number of free users. But the more users they acquire, the lower the conversion percentage dips. Suddenly the startup is facing titanic operating costs, all shouldered by a relatively tiny number of actual customers.
The best example of this trap is a product I use more than I would like to: Reddit. In 2012, Reddit had 32 billion page views. But according to the best numbers I could find (which are admittedly very dated) their premium offering (“Reddit Gold”) attracts less than .1% of users [3][4] When you take a look at what Reddit gold offers, it’s not hard to see why:
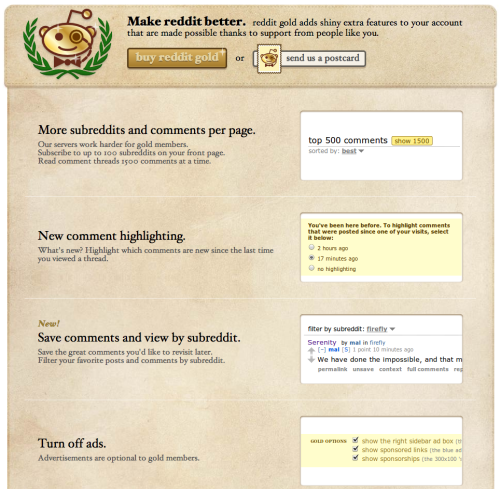
If I pay Reddit $3/month, I can turn off (unobtrusive) ads and… save and highlight comments?
The Reddit and DailyBurn premium programs have one key thing in common: they’re a set of (basically random) tacked on features that only appeal to the most power of power users. Both of the core products solve a clear and urgent need (how do I lose weight, and how do I find cat pictures). But the premium products solve a minor problem for a small minority of users.
And that explains the diminishing returns to scale: not only are 97% of your users never going to care about saving comments, but even worse – the people who are most likely to become super-power users are also most likely to be early adopters. So if you design your premium program to only appeal to power users, you should expect that conversion rates will drop with each new cohort of increasingly unsophisticated users.
If you ignore that fact, you may very quickly find yourself learning the old economic truism that “anyone can sell a dollar for 99 cents.”
The Right Way:
What’s the alternative? From day one, you should think of your free product as a way to foster addiction to your premium product, ideally by creating a behavior pattern that will naturally and inevitably lead to needing premium-only features. Your free product should make your user aware of two things:
1) You have a burning need
2) I have a way to actually solve it if you give me some money
If you stop thinking in terms of free vs. premium and starting thinking in terms of “problem understood” vs. “problem solved”, you’ll find it much easier to actually drive up conversions and turn users into customers instead of costs. Which is the whole point of your business.
The best example I know of freemium done right is Amazon’s AWS. I bet you can immediately recall AWS’s de facto tagline “a great, cheap way to start a company with no upfront capital costs.” Amazon has pushed that message very hard and very effectively. But here’s the problem: AWS is actually not cheap. It’s only cheap AT FIRST.
Amazon offers a “free tier” that lets you spin up a few virtual machines with a little bit of storage (about enough to host a low traffic blog), all for free. This encourages users to familiarize themselves with the service, and that experience makes it easy for them to image how awesome it would be to run a entire serious startup on AWS. Many startups, including mine, do exactly that.
But once you’re a few months in and you’ve added a few more instances and a database, the bills suddenly jump. And you very quickly notice that running a more powerful EC2 instance for a year is about 5-10x more expensive than just buying a comparable machine. And storage on EC2 (which you’re probably going to need for that database) costs $0.10/GB/MONTH! You can buy a 1TB hard-drive for what it costs to host 1TB of data on EC2 for one month.
From my perspective as the guy writing the checks, this model is painful. But from Amazon’s perspective it’s brilliant. By the time I actually experience the real cost of using AWS it’s far too late for me to switch. I’m addicted.
And to add insult to injury, AWS cuts off the free tier after one year of usage. They figure that after a year you’ve probably already told all your friends about AWS, and if by then you still haven’t gotten addicted then you’re probably never going to. So there’s no reason to continue to subsidize your use.
The other freemium products I pay for work the same way: anyone who has 5GB of stuff to store in Dropbox will pretty soon generate a sixth GB; if you start storing all your code in Github, eventually you’ll want to keep some of it private; if you replace iTunes with Spotify, eventually you’ll want to listen to music on your iPhone and need premium.
Conclusion:
There are plenty of perfectly good reasons to want a lot of permanent free users. They’ll tell their friends, and as Fred Wilson points out you can show advertising. They may even generate the content that brings people to your site. But with a $2 CPM, you’ll make about as much from 5000 users paying $100/year as you would from two hundred fifty million ad impressions.
At the very beginning of a startup, it would be foolish to focus excessively on exact monetization strategies before you’ve demonstrated that you can create monetizable value. And many businesses have started with free and then found pockets of value they could charge for. Nevertheless, a little thought at the beginning can go a long way. Especially if you’re addressing a niche market, it makes a lot more sense to drive up your conversion rates by designing your free product to addict customers to paying you.
Normal
0
false
false
false
EN-US
JA
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:”Table Normal”;
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:””;
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin:0in;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:12.0pt;
font-family:Cambria;
mso-ascii-font-family:Cambria;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Cambria;
mso-hansi-theme-font:minor-latin;}
[1] Obviously subject to ethical and other constraints
[2] Although DailyBurn is not nearly the most egregious freemium offender, I picked them as an example because a) I actually use them but never see myself upgrading and b) they’ve pivoted to become a protein powder company, which I’m assuming means their freemium model did not work as hoped.
[3] http://techcrunch.com/2010/07/13/reddit-gold-update/
[4] Of course Reddit also monetizes through advertising
(With Spotify playlist! Click: Best Albums 2012)
LIST:
40 Blunderbuss – Jack White
39 Open Your Heart – The Men
38 Trouble – Total Enormous Extinct Dinosaurs
37 Lion’s Roar – First Aid Kit
36 Centipede Hz – Animal Collective
35 Mature Themes – Ariel Pink
34 Oshin – DIIV
33 Port of Morrow – The Shins
32 Life is Good – Nas
31 Put Your Back N 2 It – Perfume Genius
30 Sweet Heart, Sweet Light – Spiritualized
29 Bloom – Beach House
28 Channel Orange – Frank Ocean
27 The Haunted Man – Bat for Lashes
26 XXX – Danny Brown
25 Lonerism – Tame Impala
24 Drop Gloss – Battles
23 Kill For Love – Chromatics
22 Putrifiers II – Thee Oh Sees
21 III – Crystal Castles
20 Slaughterhouse – Ty Segall Band
19 Allah-Las – Allah-Las
18 Orbits – Starkey
17 Fear Fun – Father John Misty
16 Swing Lo Magellan – Dirty Projectors
15 Bend Beyond – Woods
14 Shields – Grizzly Bear
13 End of Daze EP – Dum Dum Girls
12 Sun – Cat Power
11 Good kid, m.A.A.d City – Kendrick Lamar
10 Get Disowned – Hop Along
9 Ugly – Screaming Females
8 I Bet on Sky – Dinosaur Jr
7 R.A.P. Music – Killer Mike
6 Devotion – Jessie Ware
5 Transcendental Youth – the Mountain Goats
4 Something – Chairlift
3 Yellow & Green – Baroness
2 Attack on Memory – Cloud Nothings
1 Celebration Rock – Japandroids
Worst Album of the Year: The Money Store – Death Grips
Music Video of the Day: Hooray for Earth, “Never/Figure”
Cover of the day, Megadeth’s “A Tout Le Monde” performed on the cello